
In Part 1, we shared why we’re migrating a working GCP data platform to AWS, how we evaluated technology options, and why we decided to build a modern Lakehouse on top of Iceberg. Now we’re at one of the most critical steps in the journey: getting data reliably into the Lakehouse.
On paper, this should be simple — stream data into S3, create some tables, and call it done. In reality, every decision we make at this stage has ripple effects on the entire platform: storage layout, schema management, governance, cost, even the shape of downstream pipelines.
Over the last few weeks, we’ve been exploring different ways to land data. The simplest path is to have Debezium write directly into Iceberg tables using an Iceberg sink. It’s elegant and low-latency: data lands, becomes instantly queryable, and we move on. But that simplicity forces us to confront a bigger question: how much complexity should the Lakehouse have at the point of ingestion?
Do we just take everything as-is — invalid events, broken schemas, duplicate messages — and let downstream jobs sort it out later? Or do we validate early, reject or quarantine bad records, and keep the Lakehouse clean from the start?
And here’s where storage format enters the picture. The way we store data on S3 determines what’s even possible at ingestion time — which connectors we can use, how we enforce schemas, and whether we can commit transactions safely. This means we can’t really separate “where we land the data” from “how we land it” — the two decisions shape each other.
Extracting Data from the Source
Our main data source is the production platform itself. The platform exposes events using the outbox pattern: services write data events into a dedicated outbox table in the main MySQL database. This guarantees strong consistency between the data stored in source system and delivered to Data platform.
This pattern has worked well for us, and we don’t plan to change it during migration—for two reasons:
- It avoids extra work for the platform team.
- It ensures full compatibility with our existing pipeline, which must keep running in parallel during the migration.
Historically, we’ve used Debezium to read the outbox table. But our current setup relies on an embedded Debezium connector inside a custom-built application that pushes events into Google Pub/Sub. This design is now showing its age: the embedded connector is long discontinued, it ties us to old versions of MySQL, and it forces us to maintain unnecessary application code.
For the migration, we want to stay with Debezium—it has excellent support for the outbox pattern—but we’ll move to the latest releases. This gets us better stability, compatibility with newer database versions, and simpler infrastructure.
Here’s how our outbox table looks like:
CREATE TABLE IF NOT EXISTS outbox (
id CHAR(36) NOT NULL,
aggregatetype VARCHAR(255) NOT NULL,
aggregateid VARCHAR(255) NOT NULL,
type VARCHAR(255) NOT NULL,
`schema` TEXT,
payload MEDIUMTEXT,
PRIMARY KEY (id)
);If you’re familiar with Debezium’s example outbox table, you’ll notice ours is almost identical. The main difference is that our payload column stores the event serialized as JSON, while the schema column holds the Avro schema for that event. We’ll come back to how we handle those schemas later in the post.
At this point, the main choice we face is how Debezium delivers events:
- Using the standard Debezium Kafka Connector, which would point us toward running an AWS MSK (Managed Streaming for Kafka) stack.
- Or using Debezium Server, which skips Kafka and writes directly into many supported sinks, including S3, Kinesis, or databases.
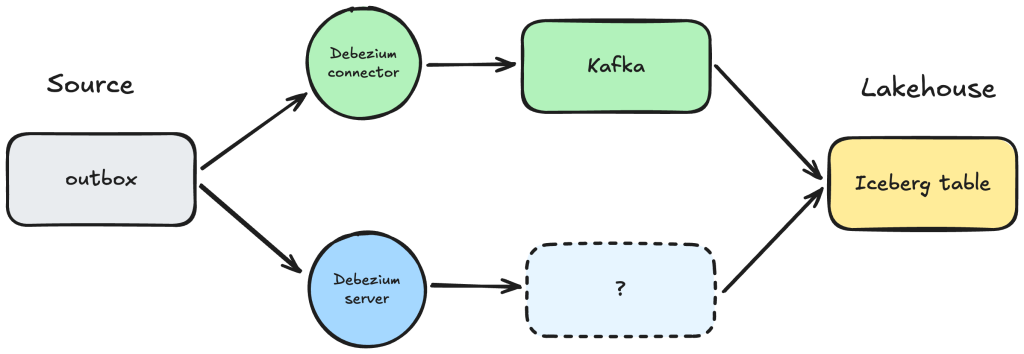
This decision shapes the rest of the ingestion design—and, as we’ll see, connects directly to how we structure the Lakehouse itself.
Streaming Through Kafka (MSK)
Kafka has become the industry standard for event streaming, and we already have experience operating it from the past. It’s a powerful system with rich ecosystem support—but it’s also more complex to run and maintain than fully managed alternatives like Pub/Sub or Kinesis.
That said, Kafka itself has evolved a lot in recent years. The removal of ZooKeeper, performance improvements in tiered storage and replication, and stronger observability features make it more attractive than ever. On AWS, MSK has also matured, offering new deployment models and management options. All of this makes Kafka worth revisiting as we design the ingestion pipeline.
In this chapter, we’ll focus on two key challenges we need to solve when using Kafka
Handling Schema Evolution
In our model, event schemas are defined by the data platform (consumer side) using Avro. Whenever new data needs to be added, we update the schema contract, ensuring it remains backwards compatible. This way, source systems can release changes on their own schedule without tight coordination, and without breaking downstream pipelines during rollbacks or delayed deliveries.
The catch: our outbox table stores data as JSON, while we need Avro to make schema evolution safe and enforce validation. That leaves us with two main options:
- Producer-side conversion Convert outbox JSON into Avro before publishing to Kafka. This would likely require a custom Debezium transformation, but would let us integrate with Schema Registry and enforce schema validation at ingestion.
- Consumer-side conversion Keep publishing JSON into Kafka, then convert to Avro before writing data into downstream systems. This resembles our GCP setup, but it means maintaining custom code since existing tools don’t support this natively.
Producer-side conversion is cleaner from a governance perspective—it ensures invalid data never even lands in Kafka in the first place.
Writing to Iceberg Tables
Once we solve schema evolution, the next challenge is writing those events into Iceberg. We looked at three main options:
Kinesis Data Firehose – The simplest option, with built-in delivery to Iceberg. However, it lacks advanced schema evolution support (currently only in limited preview) and doesn’t natively handle Avro or Schema Registry. Lambda-based transformations are possible, but they come with performance limitations. After consideration, this option doesn’t seem able to handle our slightly more complex use case.
Kafka with Iceberg Sink – Iceberg provides an official Kafka sink, with reasonable defaults and active development. There’s even a recent hands-on guide showing how to set it up. This is a promising middle ground: relatively straightforward and well supported, but still flexible enough to grow with us.
Custom Flink Application – Flink has first-class integration with Iceberg (docs) and is widely regarded as the preferred streaming framework on AWS. With Flink, we could implement schema handling exactly the way we want—similar to our GCP pipeline—but it would also require the most engineering effort to build and operate.
Using Debezium Server
Coming from the Kafka discussion, the most natural alternative we considered was using Debezium Server to stream data into Kinesis. This approach overlaps heavily with the Kafka setup—same ingestion model, similar challenges—but doesn’t really solve the key issues we care about. In fact, schema management is even trickier here: AWS Glue Schema Registry is supported only via specific producer (KPL) and consumer (KCL) libraries, which limits flexibility.
That led us to explore other destinations supported by Debezium Server. One of the most interesting options we found was the Debezium Server Iceberg consumer—an open-source project by Memiiso.
This connector does exactly what we want: capture data from MySQL and commit it transactionally into Iceberg tables. No Kafka to run, no Kinesis to tune, and no extra hops before the data becomes queryable. It keeps ingestion short and sharp.
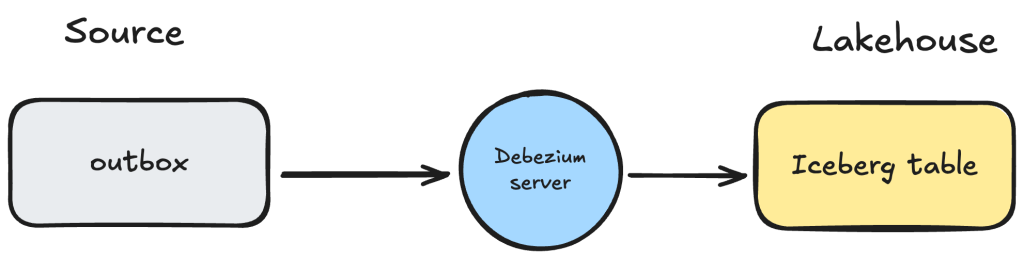
Schema validation is not included in this approach—but since we own the schema contracts, validation has always been more of a safety net than a strict requirement. What we do get is automatic schema evolution, which is the feature we care most about. Debezium Server Iceberg supports:
- Adding new columns (including nested ones)
- Expanding column types
After testing, we’re confident these capabilities are sufficient for handling the backwards-compatible schema changes we require.
Working example
To make things more concrete, here’s a simple proof-of-concept you can run locally. It uses Debezium Server to capture changes from a MySQL container and publish them directly into Iceberg tables managed in S3 / AWS Glue.
First prepare a debezium/config/application.properties file. This defines the MySQL source connector and the Iceberg sink. For details, see the documentation from Debezium server and Debezium server Iceberg.
# ====================== SOURCE (MySQL) ======================
debezium.source.connector.class=io.debezium.connector.mysql.MySqlConnector
debezium.source.topic.prefix=dev
debezium.source.database.hostname=mysql
debezium.source.database.port=3306
debezium.source.database.user=backend
#debezium.source.database.password=${MYSQL_PASSWORD}
debezium.source.database.server.id=223344
debezium.source.database.server.name=localdev-db8
debezium.source.database.include.list=poc
debezium.source.table.include.list=poc.outbox
# Start from binlog position and avoid re-snapshotting data rows (schema-only)
debezium.source.snapshot.mode=schema_only_recovery
# Offsets & DB history stored in Iceberg
debezium.source.offset.flush.interval.ms=0
debezium.source.offset.storage=io.debezium.server.iceberg.offset.IcebergOffsetBackingStore
debezium.source.offset.storage.iceberg.table-name=debezium_offset_storage_table
debezium.source.schema.history.internal.iceberg.table-name=debezium_database_history_storage_table
# ======================== SINK (Iceberg) ========================
debezium.sink.type=iceberg
# Iceberg sink config
debezium.sink.iceberg.table-prefix=debeziumcdc_
debezium.sink.iceberg.upsert=true
debezium.sink.iceberg.upsert-keep-deletes=true
debezium.sink.iceberg.write.format.default=parquet
# Glue catalog + S3 warehouse
debezium.sink.iceberg.type=glue
debezium.sink.iceberg.catalog-name=iceberg
debezium.sink.iceberg.table-namespace=icebergdata_poc
debezium.sink.iceberg.warehouse=s3://${ICEBERG_BUCKET}/
debezium.sink.iceberg.io-impl=org.apache.iceberg.io.ResolvingFileIO
# ===================== CONVERTERS/FORMATS =====================
debezium.format.value.schemas.enable=true
debezium.format.key.schemas.enable=true
debezium.format.value=json
debezium.format.key=json
# No schema change messages
debezium.source.include.schema.changes=false
# ========================= TRANSFORMS =========================
# Apply DDL filter, then Outbox router (no unwrap needed)
debezium.transforms=filterSchema,outbox
debezium.transforms.filterSchema.type=io.debezium.transforms.SchemaChangeEventFilter
debezium.transforms.filterSchema.schema.change.event.exclude.list=CREATE,ALTER,DROP,TRUNCATE
# Limit the Outbox SMT to the outbox stream only
debezium.predicates=onlyOutbox
debezium.predicates.onlyOutbox.type=org.apache.kafka.connect.transforms.predicates.TopicNameMatches
debezium.predicates.onlyOutbox.pattern=^dev\.poc\.outbox$
# --- Outbox Event Router ---
debezium.transforms.outbox.type=io.debezium.transforms.outbox.EventRouter
debezium.transforms.outbox.predicate=onlyOutbox
# Route by the row's `type` column
debezium.transforms.outbox.route.by.field=type
# Key/payload columns from your outbox table
debezium.transforms.outbox.table.field.event.key=aggregateid
debezium.transforms.outbox.table.field.event.payload=payload
debezium.transforms.outbox.table.expand.json.payload=true
# <<< IMPORTANT: avoid ${...} so Quarkus won't expand it >>>
# Match the full routed value and reuse it as the stream/table name
debezium.transforms.outbox.route.topic.regex=(.*)
debezium.transforms.outbox.route.topic.replacement=$1
# if you really want a suffix, use: $1.events
# Normalize destination table names for Glue/Hive (required)
debezium.sink.iceberg.destination-lowercase-table-names=true
debezium.sink.iceberg.destination-uppercase-table-names=false
# ======================= LOGGING =======================
quarkus.log.level=INFO
quarkus.log.console.json=false
Next, create Docker Compose file to run Debezium Server alongside a local MySQL database:
version: '3.8'
services:
# --- SOURCE DB (your existing MySQL 8) ---
mysql:
image: mysql:8.0.39
container_name: localdev-db8
ports:
- "3306:3306"
healthcheck:
test: [ "CMD", "mysqladmin", "ping", "-h", "127.0.0.1", "-u", "backend", "-p${MYSQL_PASSWORD}" ]
interval: 3s
timeout: 5s
retries: 50
start_period: 20s
volumes:
- ./mysql/custom-mysql.cnf:/etc/mysql/conf.d/custom-mysql.cnf
- ./mysql/init:/docker-entrypoint-initdb.d
environment:
MYSQL_ALLOW_EMPTY_PASSWORD: true
MYSQL_USER: backend
MYSQL_PASSWORD: ${MYSQL_PASSWORD}
SCHEMA_NAME_PREFIX: ''
ENVIRONMENT_NAME: 'localdev'
networks:
- cdc-net
# --- DEBEZIUM SERVER with ICEBERG SINK ---
debezium-iceberg:
image: ghcr.io/memiiso/debezium-server-iceberg:latest
platform: linux/amd64
container_name: localdev-debezium-iceberg
depends_on:
mysql:
condition: service_healthy
restart: on-failure
volumes:
- ./debezium/config:/app/conf:ro # expects application.properties inside this dir
ports:
- "8080:8080"
environment:
AWS_ACCESS_KEY_ID: ${AWS_ACCESS_KEY_ID}
AWS_SECRET_ACCESS_KEY: ${AWS_SECRET_ACCESS_KEY}
AWS_SESSION_TOKEN: ${AWS_SESSION_TOKEN}
AWS_REGION: eu-central-1
# optional: pass through your MySQL password if you reference it via env in properties
DEBEZIUM_SOURCE_DATABASE_PASSWORD: ${MYSQL_PASSWORD:?Set MYSQL_PASSWORD in .env}
env_file:
- .env
networks:
- cdc-net
networks:
cdc-net:
driver: bridgeDebezium requires replication privileges on the source database. Follow the MySQL setup guide to enable binlog replication. In this example:
- Add a custom configuration under ./mysql/custom-mysql.cnf.
- Place your schema initialization scripts under ./mysql/init/.
- Create a replication user with the required privileges.
- Set up the outbox table in your test database.
Debezium Server will need access to S3 and Glue. Store the credentials in an .env file and mount it into the container:
# env.example
# quotes are not needed here for strings
MYSQL_PASSWORD=your_password_here
AWS_ACCESS_KEY_ID=your_aws_key_id
AWS_SECRET_ACCESS_KEY=your_aws_access_key
AWS_SESSION_TOKEN=your_long_session_token_string
ICEBERG_BUCKET=your_iceberg_bucket_name_hereUse an AWS user with permissions to write to Glue and S3.
Run the Example
Bring everything up with Docker Compose, insert a few rows into the outbox table, and watch them appear as new records in your Iceberg tables. At this point, you should be able to query the data directly via Athena or Spark.
For example, inserting a record into MySQL:
INSERT INTO outbox (
id,
aggregatetype,
aggregateid,
type,
`schema`,
payload
) VALUES (
'550e8400-e29b-41d4-a716-446655440000',
'Order',
'12345',
'OrderCreated',
'{"type":"record","name":"OrderCreated","fields":[{"name":"id","type":"string"},{"name":"amount","type":"double"}]}',
'{"id": "12345", "amount": 42.0}'
);…will show up in Athena as:
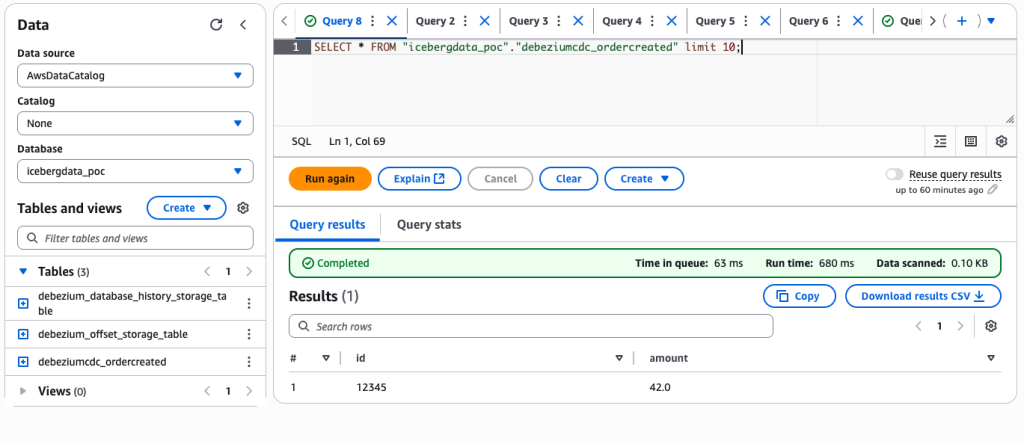
That’s all it takes to get an end-to-end pipeline working locally.
Simple, For Now
We still have to make this approach safe and production-ready. That means enforcing exactly-once delivery, preserving outbox ordering for deduplication, and running background compaction so Iceberg tables remain fast over time. If fan-out or replay requirements grow beyond this design, we can always introduce MSK or Kinesis between Debezium and Iceberg.
But for today’s goals—lower latency, fewer moving parts, and Iceberg as the source of truth—the Debezium Server Iceberg sink is shaping up to be the cleanest fit.
Storage Format
As we explore how to land data in our Lakehouse, two main options keep coming up: AWS S3 Tables or managing Iceberg tables ourselves. Both are Iceberg under the hood, so we get ACID transactions, schema evolution, and partition management either way. The real difference is in how much control we want versus how “cloud-native” we want the solution to be.
S3 Tables are about as native to AWS as it gets. AWS owns the catalog, metadata, and background maintenance (compaction, orphan cleanup, snapshot retention), which means less operational overhead and fewer moving parts for us. They plug directly into Athena, Glue, and Lake Formation (and increasingly Redshift), so security and governance are built in. The trade-off is vendor lock-in: we depend fully on AWS’s implementation and release cadence. If we ever wanted to migrate to another cloud, or adopt Iceberg features before AWS rolls them out, that could become painful.
By contrast, managing Iceberg tables ourselves means running our own catalog (e.g. Glue or Hive) and handling lifecycle tasks like compaction and snapshot cleanup. That’s more operational work, but it gives us full portability and flexibility. For example, we control schema evolution entirely: we can add, rename, or drop columns whenever we want, and we also decide when to upgrade the Iceberg table format version (from v1 to v2, and eventually v3). Format versions matter because they unlock features: v1 covers basics like schema and partition evolution, v2 adds row-level deletes and updates, and v3 (just emerging) will bring object store optimizations and stronger interoperability. In Athena today you can only create v1 or v2 tables:
CREATE TABLE my_iceberg_table (
id BIGINT,
data STRING,
ts TIMESTAMP
)
LOCATION 's3://my-bucket/my-path/'
TBLPROPERTIES (
'table_type'='ICEBERG',
'format-version'='2'In a self-managed setup, switching versions is just a table property. With S3 Tables, AWS decides the format version. Schema changes like adding columns are still supported, but if AWS hasn’t rolled out Iceberg v3, you can’t opt into it yourself. Today that’s a minor limitation — v3 isn’t widely adopted yet — but it illustrates the lock-in risk: our ability to adopt new Iceberg features depends entirely on AWS’s release cadence. With self-managed Iceberg, we evolve on our own schedule.
Right now we’re using Glue tables, mostly because the examples were easy to get started with. But as we dig deeper into table maintenance and performance tuning, S3 Tables are becoming tempting. On paper, the features sound much better — automatic file optimization, faster queries, higher write throughput — though they do come with higher storage cost. At the same time, S3 Tables are still a new service. Some blogs caution they may not yet be production-ready at scale, and even dbt doesn’t fully support creating S3 Tables via Athena today (there’s an open GitHub issue). Athena itself can work with S3 Tables, but dbt-Athena doesn’t yet handle the special catalog they use.
S3 Tables promise simplicity and better performance on paper, with AWS handling compaction, metadata, and maintenance. But they come at higher cost, tie us to AWS’s Iceberg release schedule, and don’t yet integrate with dbt — which is a deal-breaker for us. Self-managed Iceberg gives us flexibility to choose schema evolution pace, adopt new format versions when we want, and stay portable across engines and clouds, but requires us to own more of the operational burden.
Wrapping Up
For the short term, we’ve chosen the quick and simple path: Debezium Server Iceberg. It gets data flowing into the Lakehouse with minimal moving parts, low latency, and just enough schema evolution support for our current needs.
In the longer term, we still plan to move toward a Kafka-based ingestion pipeline, with full schema evolution and validation. Whether we do this during the migration or later will depend on time and priorities. This direction also aligns with our future roadmap to build new source integrations around Kafka.
With ingestion solved, we can now turn to the next stage of the journey: building transformations directly on the Lakehouse. In the next chapter, we’ll explore how we process data, optimize Iceberg tables, and ensure compatibility with BigQuery during the transition period.



