
In Part 1: Deciding to Migrate & Evaluating Options, we explored the motivations behind leaving BigQuery, the evaluation of alternative platforms, and the decision to adopt a Lakehouse model on AWS. Then, in Part 2: Ingesting Data into a Lakehouse, we focused on the early stages of building data ingestion pipelines and establishing reliable data movement from source systems into AWS.
In this Part 3 of the series, we take the next big step – bringing the Lakehouse to life. This post dives into how we stood up the first production-ready version of the platform that our users could actually start using. We’ll walk through the key updates we made to the data ingestion pipeline to make it robust and production-ready, how we structured our data storage and processing layers using AWS Athena and dbt.
By the end, you’ll get a clear view of how we transitioned from a functional prototype to a scalable, maintainable, and secure Lakehouse ready to serve analytics and business users in production.
Changing Debezium Server
In Part 2, we demonstrated a proof of concept for ingesting records from a database outbox table directly into AWS Iceberg tables using the Debezium Server Iceberg project. While this approach worked well for simple, JSON-based data, we quickly ran into challenges once we began handling our real-world datasets, which are originally Avro records rather than pure JSON.
In our case, the source systems write each outbox record as a combination of a schema and a JSON representation of the record. This design works fine for many use cases, but it created unexpected complications once Debezium started processing and writing the data to Iceberg.
One major issue involved logical Avro types, such as Decimal, which are stored as bytes in Avro. When converted through Debezium’s JSON-based pipeline, these values become string representations of byte arrays—effectively unreadable and unusable without additional transformation logic. This broke downstream queries and made it clear that our ingestion layer wasn’t handling Avro semantics correctly.
Another problem emerged with optional struct fields. The Debezium Iceberg consumer generates an Iceberg schema entry like:
71: monitoringEvents: optional struct<>While this schema is technically valid in the AWS Glue Data Catalog, it fails at runtime when writing data to Parquet, which does not support struct types with no fields. This resulted in errors such as:
org.apache.parquet.schema.InvalidSchemaException: Cannot write a schema with an empty group:
optional group monitoringEvents = 19 {
}This behavior appeared to stem from Iceberg’s current handling of certain edge cases rather than a misconfiguration on our end. We even reproduced a similar issue with PyIceberg, encountering:
pyarrow.lib.ArrowNotImplementedError: Cannot write struct type 'monitoring_events' with no child field to Parquet.At this point, it became clear that we were fighting the wrong battle. Rather than patching each of these serialization and schema issues individually, the more sustainable solution was to address the root cause—the mismatch between our data format (Avro) and the JSON-based ingestion flow. The logical next step was to handle the data as Avro from the start, allowing us to preserve schema fidelity and eliminate the brittle transformations altogether.
Avro record conversion
The fix was to make Debezium use the Avro schema as the primary source of truth when building the Connect record, instead of trying to guess from the JSON.
The source systems already write each outbox row as two columns:
- payload – a JSON representation of the event (including nested structures, unions, etc.).
- schema – the Avro schema for that event as a JSON string.
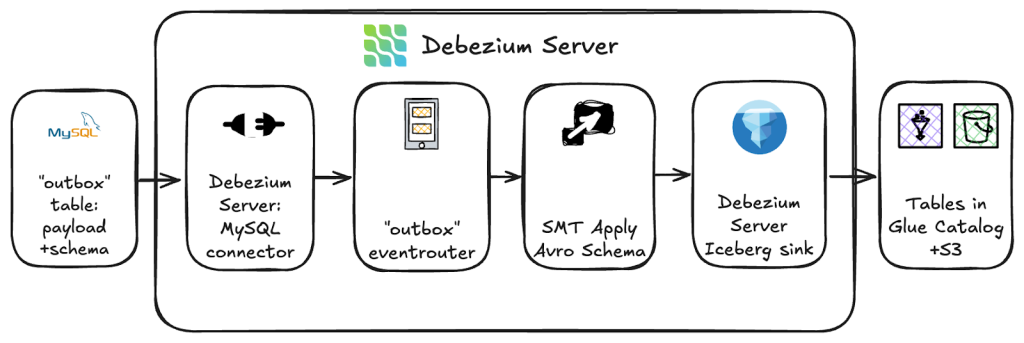
Wiring Avro into the Debezium pipeline
We did this by inserting a custom SMT, ApplyAvroSchemaTransform, into the Debezium Server transform chain.The relevant parts of the configuration look roughly like this:
debezium.transforms=outbox,applyAvro
# Outbox routing: expand JSON payload, keep the Avro schema
debezium.transforms.outbox.type=io.debezium.transforms.outbox.EventRouter
debezium.transforms.outbox.table.field.event.payload=payload
debezium.transforms.outbox.table.expand.json.payload=true
debezium.transforms.outbox.table.fields.additional.placement=schema:envelope:schema
# Apply Avro schema on the value side
debezium.transforms.applyAvro.type=com.example.transforms.ApplyAvroSchemaTransform$Value
debezium.transforms.applyAvro.avro.schema.field=schema
debezium.transforms.applyAvro.unwrap.union.json=trueThe MySQL connector reads change events from outbox table and passes them into Debezium Server. From there, the Outbox EventRouter takes over: it expands the payload JSON into a nested Kafka Connect Struct, and it copies the schema column from the outbox row into the Debezium envelope as value.schema.
Our custom ApplyAvroSchemaTransform SMT is the next step in the chain. It reads value.schema as Avro, converts that Avro schema into an equivalent Kafka Connect schema, and then reprojects the expanded payload into that schema, taking care of logical types (decimals, timestamps, unions, bytes) along the way.
At the end of this path, the sink (Iceberg today, Kafka + Schema Registry later) receives a fully typed Connect record.
Practically, this solved the original problems:
- Decimals arrive as real decimals, not opaque byte strings.
- Nested structures no longer degrade into strange empty structs.
- The schema in the raw layer matches the same Avro contracts that producers use and that we convert into Iceberg DDL
Just as importantly, it sets us up for the next step in the migration: once we introduce Kafka and Schema Registry, we can largely keep the same contracts and transformation logic, and just change where Debezium sends these Avro-shaped records.
Raw tables conversion
When we started ingesting data into Iceberg tables, we quickly ran into several schema-related challenges. Debezium is excellent for capturing change events and writing them into Iceberg tables, but its on-demand schema handling isn’t a great fit for our production setup, which relies on well-defined schemas deployed ahead of time.
The main issue is that Iceberg tables don’t exist until data actually arrives. If no record has been produced yet for a given table, it simply isn’t created – and the same goes for schema evolution. New or changed fields only appear once an event containing them is processed. In our environment, where not all source systems emit data continuously, this would mean we couldn’t deploy new data models or transformations in advance; we’d be stuck waiting for the schema to “evolve” at some unpredictable time.
To address this, we decided to take control of schema creation ourselves. Instead of relying on the Iceberg sink to infer or evolve schemas automatically, we now use the same Avro data contracts used by source producers as the single source of truth. Based on these, we built an internal tool that converts Avro schemas into Iceberg DDL definitions and creates all raw tables ahead of ingestion.
This tool handles several important details:
- Field and element IDs: Iceberg requires explicit field IDs for all fields, and additional IDs for elements in arrays and maps. The converter generates these automatically to ensure compatibility (especially when using PyIceberg).
- Custom logical types: Some of our Avro contracts include reusable logical records such as SerialId. The converter resolves and normalizes these so they can be correctly represented in Iceberg.
- Partitioning: Partitioning isn’t a standard feature of the Debezium Iceberg consumer – it simply writes to existing tables. Without our schema-generation tool, all tables would be created unpartitioned by default. By defining partitioning rules (for example, day-based partitions on timestamp columns) directly during schema creation, we ensure every raw table is optimized for query performance and consistent across environments.
During early testing, we encountered some unexplained write failures in the Iceberg sink component when inserting data into newly created tables. Although the exact cause remains unclear – likely a bug in the third-party Iceberg consumer – we found that marking all fields as optional avoided the issue and allowed ingestion to proceed normally.
Overall, this approach gave us a much stronger foundation for the raw data layer. By generating Iceberg tables directly from Avro schemas, we’ve decoupled schema deployment from runtime ingestion, ensured consistency with the contracts used by producers, and established a repeatable, controlled process for managing schema evolution across all environments.
Athena and data transformations
Once the data ingestion pipeline was up and running, the next challenge was building out the transformation layer. In our GCP setup, most transformations were implemented as Spark applications, some of them quite large and complex – but mostly legacy setups created back in Hadoop times. For the migration to AWS, we decided to rethink this approach. Many of the crucial transformation jobs could be expressed in SQL, and since we already planned to use dbt for managing our data warehouse models, it made sense to migrate as much of the transformation logic as possible to dbt as well.
Overall setup
We use dbt Core together with the dbt-athena adapter, which allows us to define and execute SQL models directly on top of Iceberg tables in Athena. The dbt project and model logic are stored in Git, and the transformations are orchestrated via Argo Workflows. Each workflow triggers dbt commands inside a container, giving us full control over scheduling, dependency handling, and environment setup.
To run models across multiple environments, we use different dbt profiles for each environment. In our Argo Workflows, both the target environment and Git branch are passed as parameters – for example, the develop branch can run in the dev environment, or a feature branch can be tested independently. This setup gives us a clean and flexible way to test new versions without maintaining multiple dbt projects or directories, and since transformation changes don’t happen very often, it’s been an easy setup to maintain.
Incremental models and Iceberg partitioning
One of the first issues we hit was with incremental models that process more than 100 partitions. Athena currently has a hard limit on the number of partitions that can be scanned in a single query (100 by default), which becomes a real problem for large fact tables partitioned by date or event type. This required some redesign in how incremental logic is written – batching processing windows or limiting by partition values rather than scanning the entire dataset. It’s a known Iceberg + Athena limitation, but one worth keeping in mind when working with large-scale incremental models.
Iceberg partitioning itself also comes with a few subtleties. Different query engines perform partition pruning differently, so it’s important to write WHERE conditions that align with how the engine interprets the partition column. For example:
WHERE DATE(partition_column) > '2025-11-05'might not prune partitions properly in Athena, while
WHERE partition_column > '2025-11-05'will. Small differences like these can have big performance implications when scanning large datasets.
Cross-Account execution and roles
Another challenge was setting up cross-account execution. We have a single Argo Workflow running in one AWS account, but dbt models need to run across multiple accounts that represent different environments (dev, stage, prod). This required careful setup of cross-account IAM roles and assume-role policies, ensuring that each dbt run executes with the correct permissions in the target account. Once this was in place, orchestration became much cleaner – Argo triggers dbt jobs in the correct environment without accessing stored credentials.
Historical data migration
One more important topic during the transformation migration was historical data – it’s essential for analytics and reporting, so we needed a way to bring it over quickly and reliably. The fastest and simplest approach we found worked surprisingly well.
We focused first on a few high-value tables, starting with one of our transactional datasets, and followed this basic workflow:
- Export data from BigQuery to GCS as Parquet.
Used BigQuery’s EXPORT DATA to dump a few months of data into partitioned Parquet files. - Transfer the Parquet files to S3 using an EC2 instance.
The instance had access to both GCS and S3 and copied files directly between them using standard tools like the Google Cloud SDK and the AWS Command Line Interface (CLI), avoiding any local downloads. - Register the data as Iceberg tables in Athena.
Once files landed in S3, we created Iceberg tables pointing to them. For quick validation, we used a Glue crawler, but future runs will likely rely on DDL-based table creation to keep schema definitions versioned in code.
This process came with a few minor challenges – mostly around data type differences between BigQuery and Iceberg. The only real adjustment needed so far was timestamp precision, since Iceberg expects microsecond (timestamp(6)) precision, while BigQuery exports millisecond timestamps. After normalizing those fields, everything else worked as expected.
Overall, this straightforward workflow made the first batches of historical data available in Athena and ready for dbt transformations, without adding any unnecessary tools or complexity.
Closing
With these changes in place, we now have the first production-ready version of client’s new Lakehouse – a platform that analysts and downstream systems can already start using. The ingestion layer is stable, schemas are controlled through Avro contracts, Iceberg tables are created deterministically, and our dbt-on-Athena transformation pipeline runs reliably across multiple AWS environments using Argo Workflows.
This foundation gives us far better transparency, maintainability, and control than the previous Spark-heavy BigQuery setup. It’s fully versioned, easy to deploy, and much simpler to extend as new datasets or transformation logic emerge.
That said, the migration is still ongoing. Compatibility between the old BigQuery environment and the new AWS Lakehouse remains an open topic, as not all internal systems have been migrated to consume data from AWS yet, therefore this compatibility layer is a must. As more teams adopt the new platform and pipelines are redirected to AWS, the remaining BigQuery components will gradually be phased out.
But the most important milestone has been reached: the core Lakehouse architecture is up, the workflows are running, and the data is available. From here, we can continue refining governance, performance, and user experience – and steadily migrate the remaining workloads to complete the transition.In the next part of the series, we’ll dive into the governance layer, curated models, and the compatibility layer that helps us operate across both platforms during the transition. With the foundation in place, the work now shifts toward strengthening, optimizing, and evolving the Lakehouse.



